RapidMiner 日本語テキスト分析 実践活用編

難易度
☆★★★
深層学習編にて、テキスト分析についてご紹介しましたが、本講座では日本語のテキスト分析についてより実践的な課題を扱います。具体的には、RapidMinerのみ(Python連携せずに)で日本語の形態素解析を行いテキストの分類を行います。また、One Hot Encodingでは難しい分散表現を用いた深層学習モデルの作成を行います。日本語テキストを使ってノンプログラミングでより高度な実践例をご紹介しております。
対象者
日本語でのテキスト分析をノンプログラミングで行いたい方
所要時間
約120分
習得内容
テキストデータのハンドリングができるようになる。
テキストデータを使ったより精度の高い予測ができるようになる。
コース内容
全3章 約120分
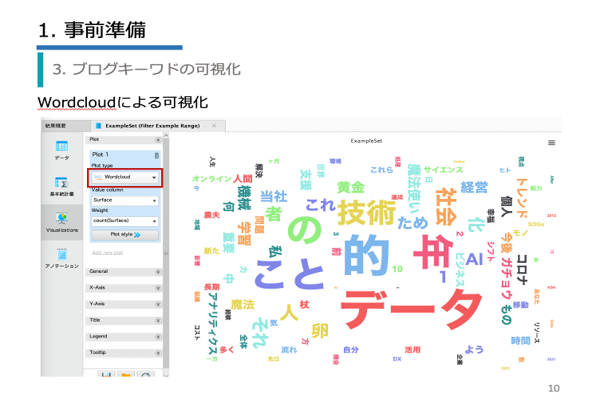
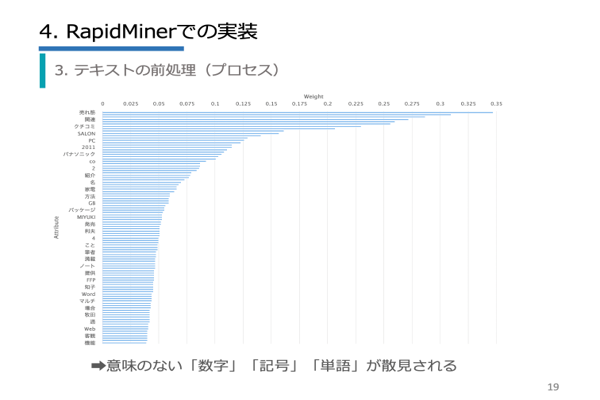
| 第1章 | 事前準備/形態素解析/環境設定/ブログキーワドの可視化/科学研究論文の分類/特許検索/問合せ情報の分類/ニュース記事の分類/RapidMinerでの実装 |
|---|---|
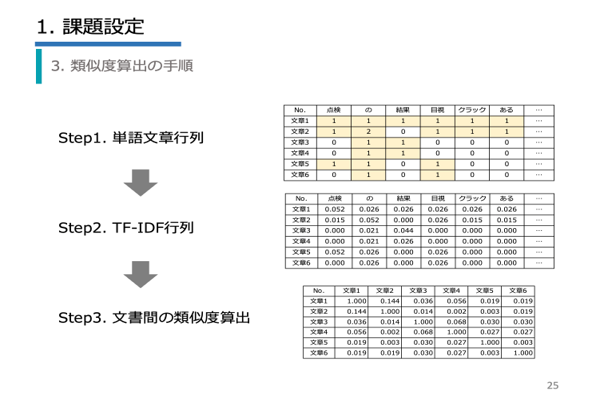
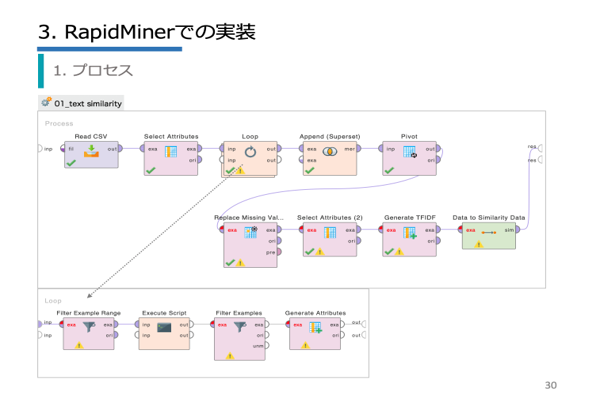
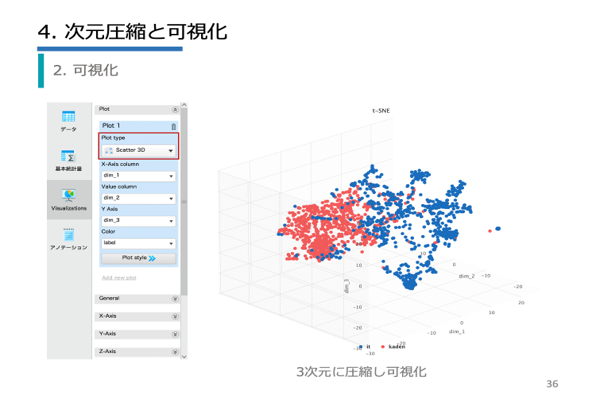
| 第2章 | 類似文章の抽出/類似性を評価/類似度算出の手順/TF-IDF/コサイン類似度/RapidMinerでの実装/t-SNE/可視化 |
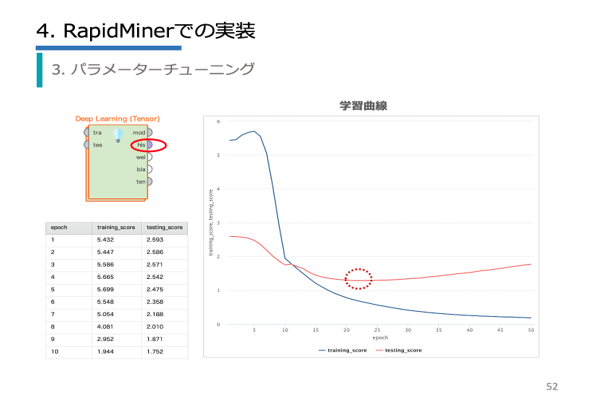
| 第3章 | 単語のベクトル表現/Word2Vec/本のタイトルの分類/形態素解析/分散表現(Embedding)/深層学習(LSTM)/深層学習モデル作成と検証/モデルの検証/パラメーターチューニング |